



Entity Footprint: un processo ed una metrica per la SEO Semantica
Non potevo lasciare sul sito, ormai dismesso e non più rinnovato, il blogpost cui ero più affezionato.

Ciao,
Quello che stai per leggere è la replica dell’articolo che avevo ospitato sul mio sito aledandrea.it, riveduta in alcune microscopiche parti. Perché l’ho postata qui? Perché ho lasciato scadere il dominio, dato che non avevo più voglia di seguirlo. Preferisco Substack.
Inizia da qui sotto. Buona lettura.
Questo è un post dove Simone Razzano ed io presentiamo l’Entity Footprint, una metrica ed un processo di lavoro generato dal laboratorio di alchimia SEO in Facile.it e presentato pubblicamente per la prima volta all’MB Summit 2022.
Ci tengo a precisare immediatamente che il processo qui descritto è nato e si sta sviluppando grazie all’aiuto di tutto il team SEO di Facile.it, effettivo o ad honorem non fa differenza. Nel dettaglio, oltre a Simone e me, il processo è nato grazie ad Elena dell’Orfanello; Linda Montemurro; Stefano Gizzi; Lorenzo Righetto; Sofia Vigo; Carmela di Matteo; Enrico Ivaldi; Marta Radavelli ed Angelica Scalzi.
Definizione: Nel campo dell’analisi semantica, l’entity footprint è una metrica che definisce la moda e la media dei ranking della Salience delle entità presenti in un gruppo di testi analizzati tramite un’API NLP, come le Google NLP API.
L’obiettivo è creare una metrica che possa aiutarci ad individuare, in maniera facile e veloce:
Gli argomenti principali in una serie di pagine.
Gli argomenti comuni ad una serie di pagine o tipici di una pagina e di conseguenza…
… le opportunità che abbiamo per rendere il nostro contenuto più ricco, esaustivo e completo.
Perché?
Che problemi puntiamo a risolvere?
L’idea che ci ha portato a formulare questa metrica nasce dal voler risolvere tre problemi fondamentali:
Capire cosa ci fosse nei contenuti competitor di così galattico da poter essere sempre posizionati meglio rispetto al nostro?
Ci mancava una metrica oggettiva e quantitativa che potesse definire la qualità del contenuto realizzato. Qualcosa che potesse andare oltre il “meglio” o “peggio”, oltre il “brutto” o “bello”, e che potesse invece descriverci con precisione il grado di completezza ed approfondimento raggiunto. La stessa metrica, poi, avrebbe anche potuto rivelarci se invece ci fossero parti da tagliare o da riformulare.
Capire cosa si potesse aggiungere di nuovo e non considerato alla nostra risorsa.
Che obiettivi ci siamo posti?
Migliorare la rilevanza di un contenuto rispetto ad argomenti specifici;
verificare che il contenuto contenga tutti gli argomenti presenti nelle pagine che rankano meglio in SERP;
identificare l’entity footprint dei contenuti analizzati;
supportare l’editor nella valutazione del proprio lavoro;
risparmiare tempo;
evitare rilavorazioni;
capire meglio il motore di ricerca e soddisfare la nostra curiosità.
Il software
Cosa abbiamo costruito?
La soluzione è stata costruire due cose:
Uno script in Python per richiamare le API, che potesse analizzare una serie di corpus testuali trasmessi via CSV. Doveva essere in cloud per essere il più flessibile possibile e restituire dei risultati esportabili via CSV.
Un template di lavoro in Google Sheets che ci permettesse di raccogliere i risultati dello script e riorganizzarli in modo da avere diversi fogli e diverse informazioni.
Importante: a prescindere dall’API che si decida di utilizzare, è fondamentale assicurarsi che l’API selezionata permetta di:
Disambiguare le entità con lo stesso nome, deducendo la tipologia in base al contesto del contenuto. (Es: ingegner Ferrari -> Person; Rosso Ferrari -> Thing; Ferrari -> Organization/Corporation).
Calcolare una Salience o Relevance Score che indichi quanto una data entità viene riconosciuta come rilevante nel documento analizzato, in modo da stabilire la footprint.
Estrapolare i riferimenti a Knowledge Graph noti (es: Wikipedia o Wikidata) delle entità individuate nel testo.
Il template in GSheet
Come detto, il template GSheet è il cuore pulsante del processo, perché è dove raccogliamo i dati, li riorganizziamo e li rendiamo potabili per tutti.
Le informazioni rilevanti sono:
Entity Matrix: l’entità è presente nel corpus testuale analizzato? L’API, grazie alla NER (Named Entity Recognition) può rivelarci questa informazione.
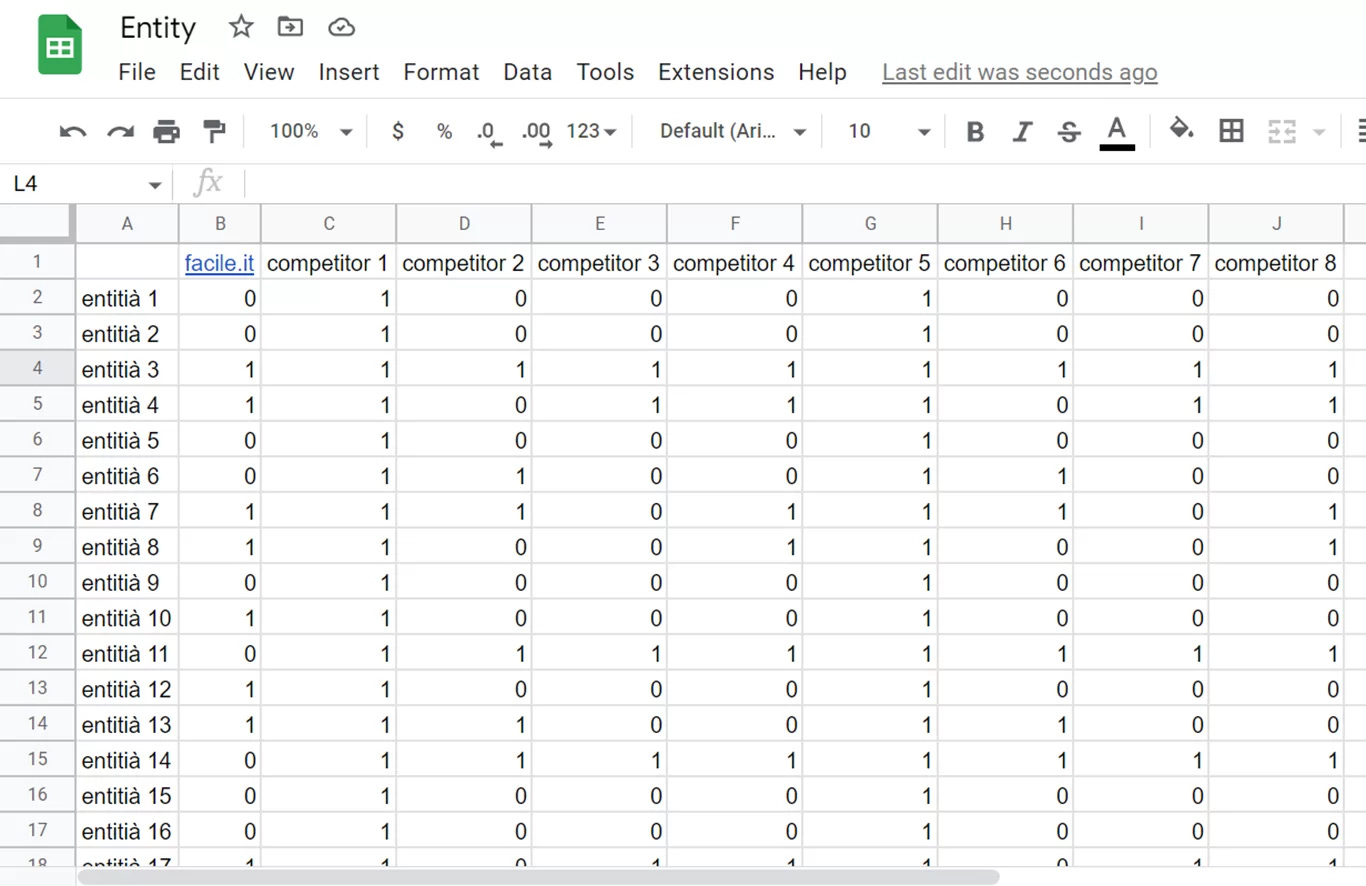
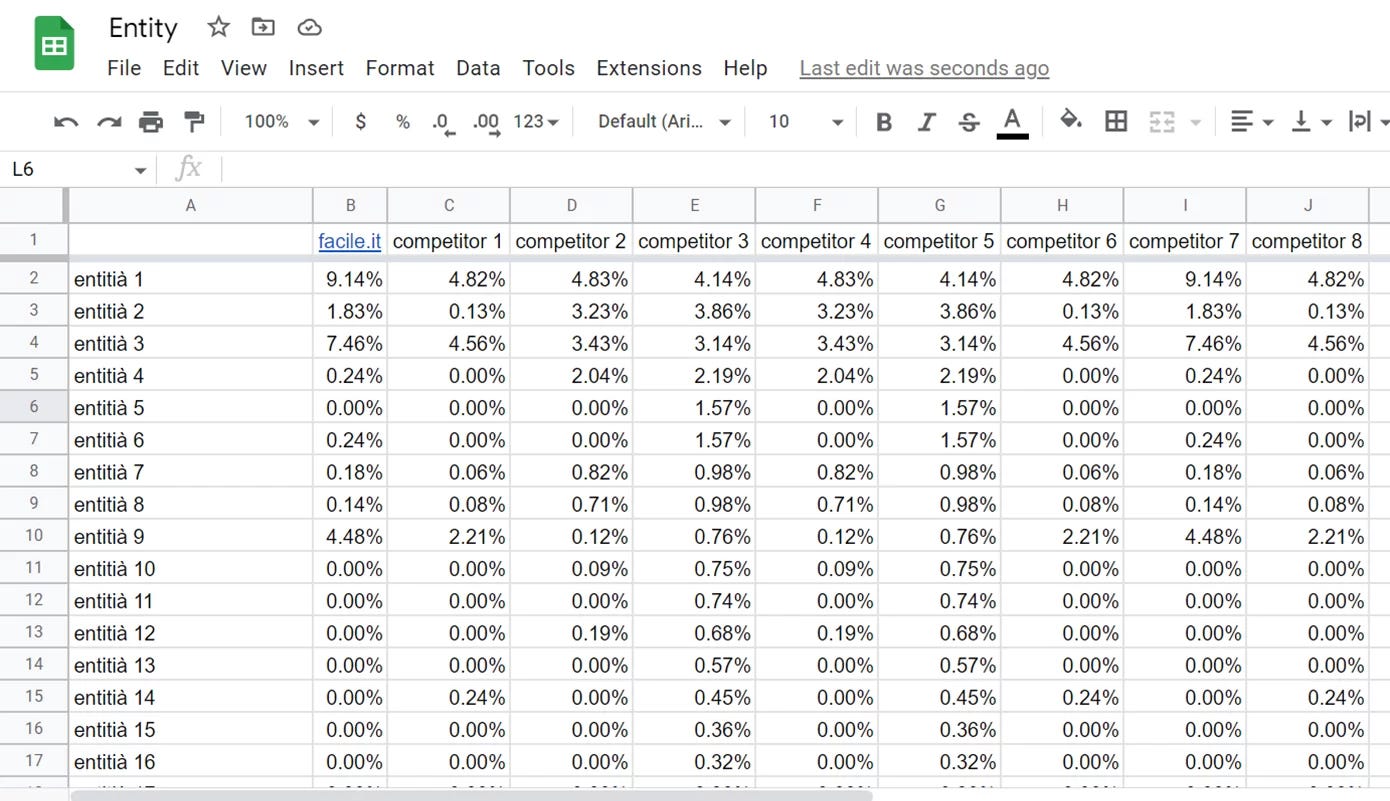
Relevance Score: quanto è importante l’entità rilevata nel bilancio di pagina? Questo parametro, nell’output delle Google NLP API viene chiamato Salience. TextRazor lo chiama invece Relevance Score.
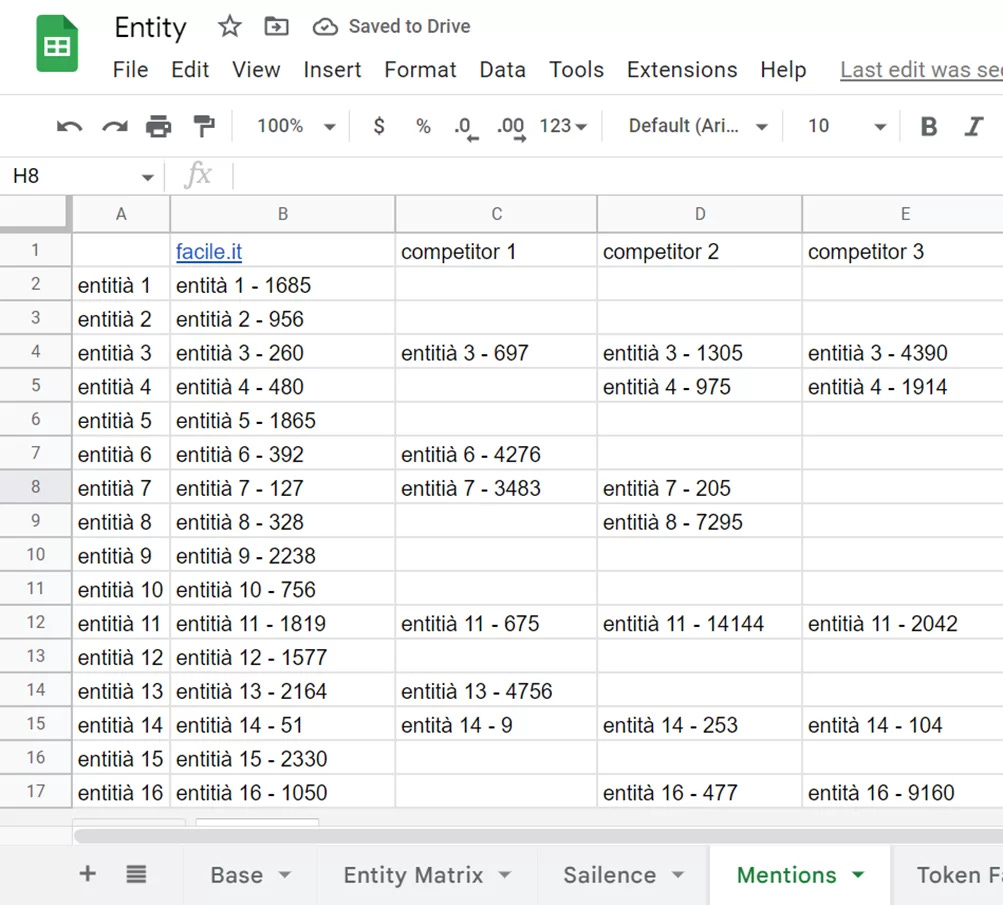
Mentions: quale parte della pagina attiva il riconoscimento di una certa entità? Questo valore ci serve per capire cosa e come l’API interpreta il documento.
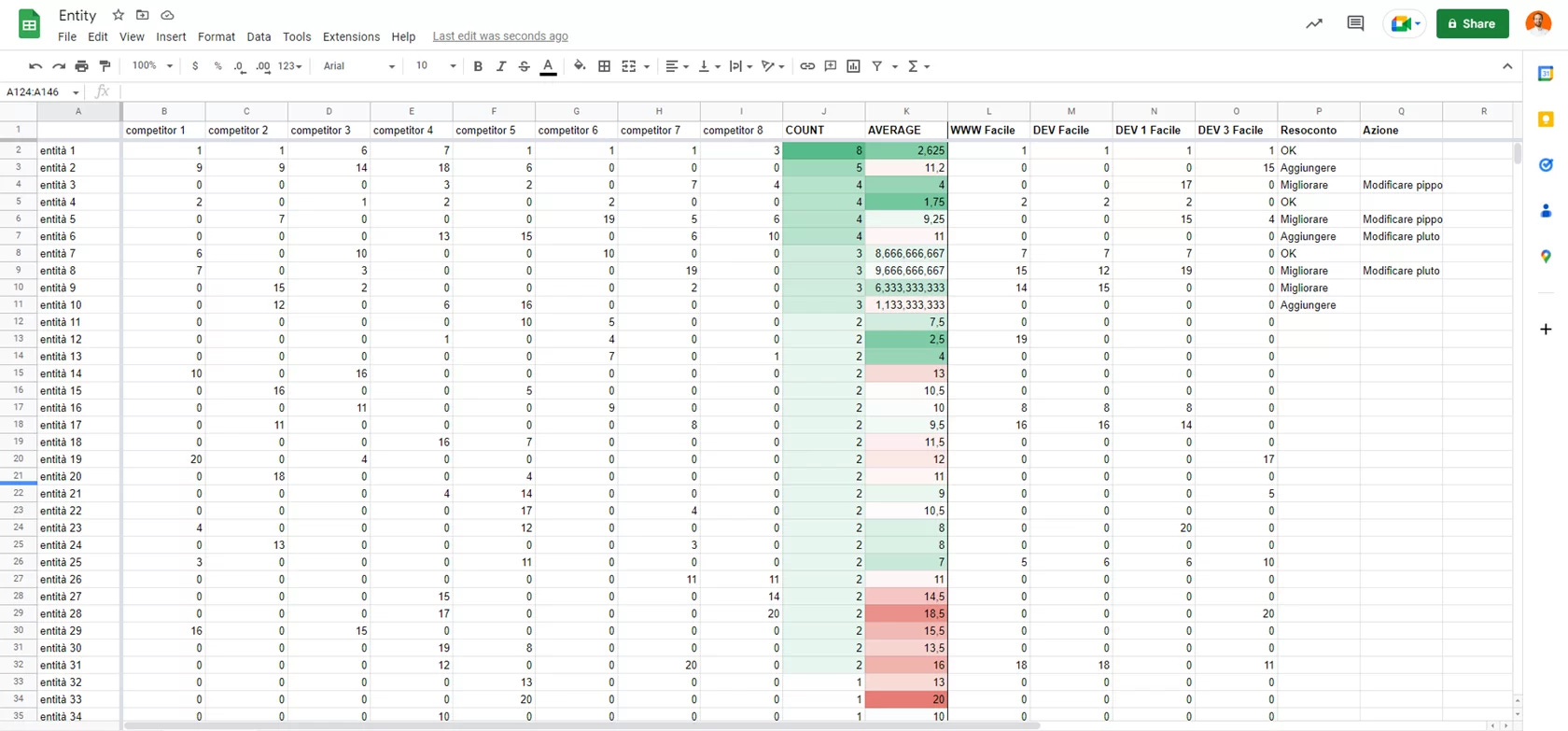
Entity Footprint: la metrica derivata che ci permette di stabilire, secondo un indice, quali entità sono più popolari all’interno del gruppo di testi analizzati, e quanto sono rilevanti se presenti nei testi confrontati.
La procedura
Aumentare la rilevanza delle entità
Per aumentare la rilevanza delle entità nel testo seguiamo 3 step:
Individuiamo le entità rilevate nei contenuti analizzati, e creiamo la footprint ordinando in un indice da 1 ad n le entità di ogni competitor sulla base del relevance score in ordine discendente.
Identifichiamo le entità non presenti o non rilevate nel nostro testo o nei testi competitor.
Identifichiamo le entità già presenti nel nostro testo, ma da migliorare. Sono quelle con un valore di indice del relevance score differente rispetto alla footprint.
Ripetiamo il processo e l’analisi via API per valutare il risultato.
L’obiettivo, quindi, è generare una entity footprint degli argomenti delle pagine, e capire quali siano gli argomenti principali delle pagine dei competitor.
Aggiungere entità mancanti o non rilevate
Le entità mancanti sono le entità pertinenti con l’argomento della pagina e rilevate negli altri contenuti che però sono completamente assenti nel nostro.
Se un’entità è completamente assente, possiamo introdurla aggiungendola al corpus testuale, quindi menzionandola all’interno del contenuto nella maniera più adatta. Ad esempio, potremmo sviluppare un paragrafo ad hoc per introdurla e contestualizzarla all’interno del contenuto.
Le entità non rilevate sono le entità pertinenti con l’argomento della pagina e rilevate negli altri contenuti, e che anche se presenti nel nostro testo non vengono rilevate dall’API.
Se un’entità è presente ma non rilevata, possiamo introdurla riformulando alcune frasi o interi paragrafi, fino al riconoscimento da parte dell’API. Potrebbe essere necessario utilizzare un nome specifico per le entità che si vogliono intercettare (es: responsabilità civile autoveicoli vs RC Auto), a causa delle capacità di tokenizzazione dell’API
Migliorare il Relevance Score delle entit�? presenti.
Sono le entità più pertinenti per l’argomento ma che non rispettano i valori della footprint.
Ne dovrebbe essere aumentata la rilevanza come da footprint scrivendo in maniera più semplice, chiara e comprensibile, così che il testo possa essere compreso ed assimilato con più facilità da un lettore.
Ad esempio, si potrebbe:
Adottare una scrittura più inglese, riducendo la lunghezza delle frasi ed adottando più punteggiatura e meno subordinate.
Modificare la struttura sintattica della frase, ad esempio preferendo l’utilizzo di forme verbali attive e non passive.
Modificare la struttura del contenuto, ad esempio giocando con la posizione dei paragrafi e provando a capire, in questo modo, se siamo efficaci nell’aumentare la rilevanza di alcuni concetti, a scapito di altri.
Rendere il testo più semplice da leggere aiuta le API nella loro tokenizzazione, e quindi nell’estrazione delle entità.
Iterazione del processo e conclusione
Continuiamo nel nostro processo:
Ripetiamo il confronto di ogni nuova versione rispetto ai competitor e rispetto alle nostre versioni precedenti.
Continuiamo a correggere.
L’obiettivo è attuare cambiamenti incrementali e controllabili che possano farci progredire un pezzetto alla volta.
Ricordiamoci sempre anche di controllare potenziali cannibalizzazioni che si potrebbero generare con altre pagine del sito, a causa della riscrittura del contenuto.
Quando termina il processo?
Il processo termina quando:
Tutte le entità mancanti nel proprio testo sono rilevate.
Le entità principali avranno una posizione ritenuta soddisfacente ed in linea con l’obiettivo della pagina.
La classifica delle entità del contenuto ricalcherà fedelmente la footprint.
Esempi concreti e risultati:
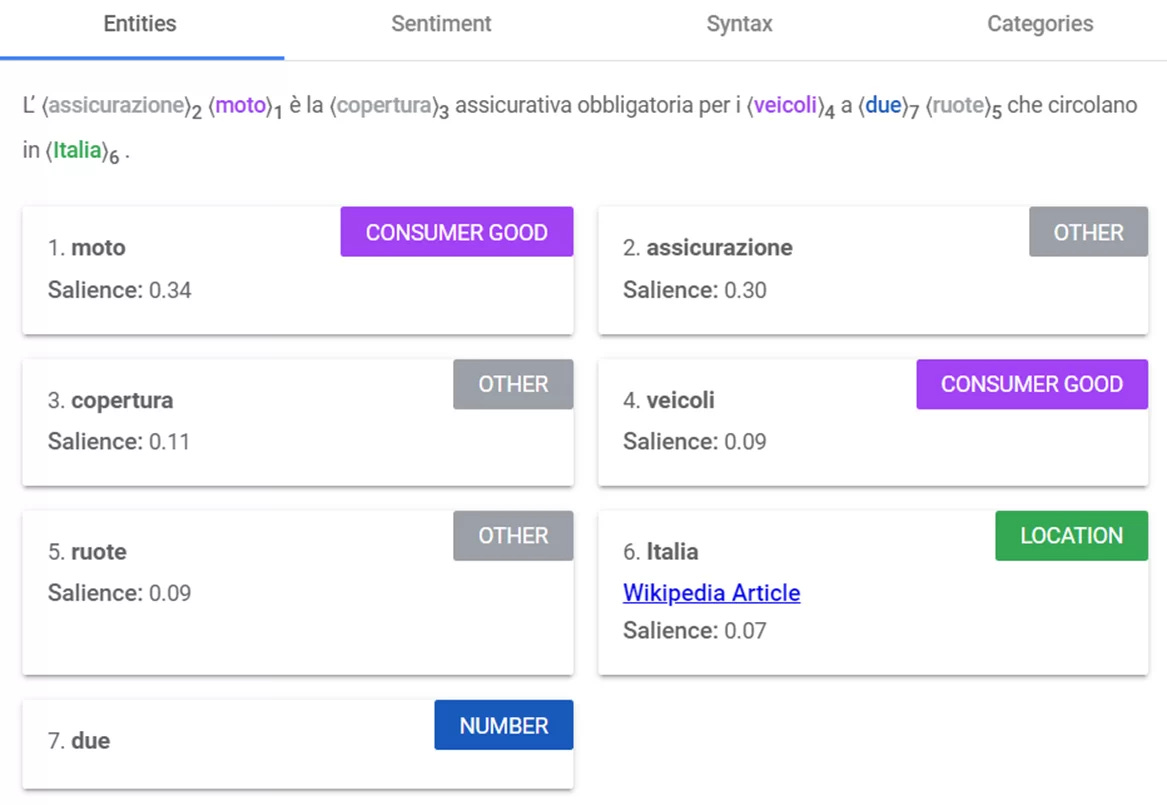
Facciamo un esempio concreto su una singola frase, per vedere come il riconoscimento delle entità cambia la Salience su una singola frase:
In Italia, per tutti i veicoli a due ruote è obbligatorio stipulare una copertura assicurativa, ossia l’assicurazione moto.

L’assicurazione moto è la copertura assicurativa obbligatoria per i veicoli a due ruote che circolano in Italia.
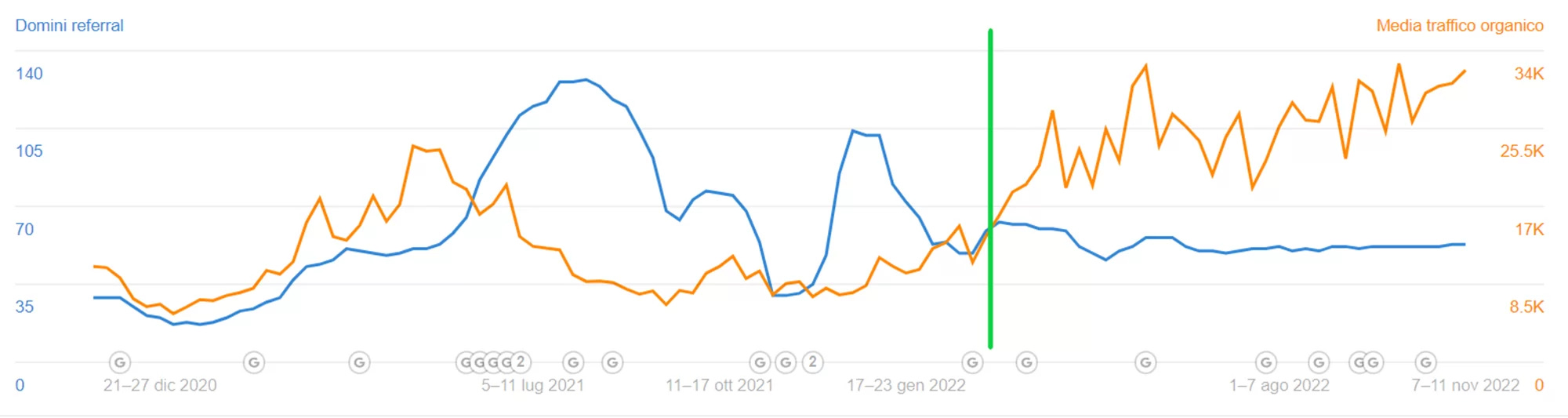
Applicare il metodo della Entity Footprint ci ha permesso di ottenere risultati interessanti sulle pagine del nostro sito. Un esempio a partire dal momento dell’applicazione, contrassegnato dalla linea verde:
Non siamo gli unici ad aver ottenuto risultati. Questo post di CXL racconta un’altra storia di successo.
Note importanti:
Non esiste una percentuale giusta per le entità.
Ripetere le keyword collegate ad un’entità non accresce la rilevanza dell’entità nel testo. Dove lo avevamo già visto? La cosa interessante è che non era la prima volta che lo vedevamo.
Confrontiamo il ranking del relevance score e non il puro relevance score perché questo può cambiare in base al contenuto ed al layout della pagina. Ci aspettiamo però che pagine che rispondano allo stesso intento di ricerca abbiano un medesimo ranking di relevance score per una stessa entità.
L’analisi si basa solamente sull’HTML renderizzato e su quanto presente all’interno del <body>.
L’analisi non considera i meta tags.
La segnalazione delle entità rilevanti tramite testo è complementare all’arricchimento del contenuto attraverso dati strutturati, ed in particolar modo attraverso l’utilizzo del dato strutturato WebPage e le proprietà:
About
Mentions
knowsAbout
sameAs
Il tool è un supporto per la scrittura, ma non garantisce alcun tipo di successo. Un o una web writer, editor o copywriter con preparazione verticale ed alta esperienza nel settore resta fondamentale.
Bibliografia ed approfondimenti ulteriori:
API per l’NLP
Information gain
NLP e tokenizzazione
https://www.tokenex.com/blog/ab-what-is-nlp-natural-language-processing-tokenization/
https://towardsdatascience.com/tokenization-for-natural-language-processing-a179a891bad4
https://www.diariodiunanalista.it/posts/bag-of-words-cosa-e-e-come-funziona/
Dati strutturati
SEO Semantica
https://inlinks.com/en/the-evolution-of-semantic-search/, in particolar modo al paragrafo “Turning Text into Mathematical Concepts”.
Video di approfondimento
Video di e Massimiliano Geraci di approfondimento sull’argomento, con case study anche relativa al semantic publishing.
Video di Valentina Izzo e Massimiliano Geraci di approfondimento sull’argomento.